Introduction to Artificial Intelligence
1) What is Artificial Intelligence?
Artificial Intelligence (A.I.) refers to technology that artificially implements some or all aspects of human intelligence. Although it has been frequently mentioned in recent years, the history of artificial intelligence is quite long.
Generally, artificial intelligence is categorized into strong AI and weak AI. Strong AI refers to AI that perfectly replicates human intelligence, but such AI has not yet been developed. On the other hand, weak AI is limited to specific purposes. Most of the AI technologies available today fall into the category of weak AI.

2) Artificial Intelligence and Machine Learning
Artificial intelligence is a broad concept that includes both software and hardware capable of performing tasks in place of human intelligence. For example, classifying products or adjusting the amount of water based on the amount of laundry are also considered applications of AI.
Machine learning refers to systems that analyze existing data and operate autonomously. Depending on how the data is created, machine learning can be classified into supervised learning, unsupervised learning, and reinforcement learning. Representative machine learning techniques include k-nearest neighbors (KNN), regression analysis, and artificial neural networks.
Deep learning is a more recent term that refers to an improved machine learning system based on artificial neural networks, which have been used for a long time in AI history. Recently, with the widespread adoption of DeepMind’s GPU-based technology, deep learning has become more commonly used.
3) Artificial Intelligence and Robots
Artificial intelligence has been frequently depicted in movies and TV dramas long before computer technology advanced enough to fully utilize AI. In such media, AI is often portrayed at the level of strong AI, typically in the form of androids that behave similarly to humans. As a result, many people tend to equate AI with robots. The reason androids appear frequently in media is that they can be easily implemented by having human actors perform as humanoids. Recently, the reverse has also been happening, where humanoid robots replace human actors for performing complex action sequences.
As mentioned earlier, artificial intelligence refers to technology that can replace human intelligence, while robots are designed to replicate or enhance human or biological physical abilities. Robot arms or cleaning robots, for example, are used to perform physical tasks that humans would normally do. Some robots resemble humans and are called humanoid robots or simply humanoids.
In movies, TV shows, and other media, robots are often portrayed as a combination of humanoid robots and strong AI.
4) Implementation Methods of Artificial Intelligence
Artificial intelligence can be classified into strong AI and weak AI, as categorized by Professor John Searle. AI has been implemented in various ways over time. Based on the method of implementation, it can be categorized as follows:
Expert Systems
Expert systems involve developers programming AI based on accumulated experience to handle various situations. For example, if an AI system determines whether an egg is defective based on its weight, color, and transparency, it is considered an expert system. Most practical AI applications today are implemented using this method.
Fuzzy Systems
Fuzzy systems transform vague or uncertain states into numerical values for decision-making. Humans instinctively make appropriate decisions based on surrounding conditions, and fuzzy systems attempt to replicate this by converting those conditions into quantifiable data.
Genetic Algorithms
Genetic algorithms mimic the process of natural evolution, incorporating mutation, crossover, and survival of the fittest to improve AI performance.
Machine Learning
Machine learning enables AI to recognize patterns and make decisions based on data rather than predefined rules. It has become the most crucial method of implementing AI today. Initially, machine learning relied on techniques like k-nearest neighbors (KNN) and regression analysis, but modern machine learning has evolved to incorporate artificial neural networks.
5) Machine Learning
Before machine learning, expert systems were the primary method for implementing AI. Developers created algorithms based on empirical knowledge. For example, an expert system might determine that an egg is defective if it is unusually light compared to its size, using predefined rules to classify the egg.
Machine learning, on the other hand, does not rely on predefined knowledge but instead learns from data. The system is provided with data and learns patterns to produce desired outcomes. For example, if an AI model is trained on a dataset of eggs labeled as either defective or non-defective, it can recognize patterns and make accurate classifications. Machine learning generally produces better results than expert systems.
Machine learning is divided into three main types based on its objective:
Supervised Learning
Supervised learning involves training an AI model using labeled data. This means the data includes both input features and the correct answers. Most AI research today is based on supervised learning because it is the most straightforward way to achieve high accuracy. However, supervised learning requires humans to create labeled datasets, a process known as “labeling.” Currently, public datasets are widely used to provide labeled training data.
Unsupervised Learning
Unsupervised learning does not use labeled data; instead, the AI model must find patterns and structure within the data. This approach is commonly used for clustering, density estimation, and recommendation systems. For example, when clustering faces in a photo collection, once one face is labeled, the AI can group similar faces and apply the same label to them.
Reinforcement Learning
Reinforcement learning involves training an AI through rewards and penalties. The model learns to maximize rewards over time, making it the most human-like learning method in terms of adaptability. However, because it relies on trial and error rather than logical reasoning, it often requires extensive training. For instance, an AI parking system trained with reinforcement learning might take hundreds of thousands of attempts before successfully parking a car.
There are various machine learning algorithms, with artificial neural networks being the focus of much recent research.
6) Machine Learning Algorithms
Regression Techniques
Regression techniques, such as linear regression and logistic regression, analyze trends mathematically based on existing data.
Probability-Based Methods
These methods make predictions based on probability. The AI calculates probabilities from existing data and uses them to determine outcomes for new data points.
k-Nearest Neighbors (KNN)
The k-nearest neighbors algorithm classifies new data by referencing the k most similar data points from the training dataset. This method works well when data is clearly separable, but in more complex cases, artificial neural networks tend to produce better results. However, KNN is simple to implement, making it a popular choice for beginners in supervised learning.
Artificial Neural Networks (ANN)
Artificial neural networks use a structure modeled after the human brain, where nodes (neurons) are connected by weighted edges. The AI adjusts these weights to improve its decision-making. Since large neural networks require extensive computation, GPUs are often used to accelerate parallel processing.
7) Artificial Neural Networks
Artificial neural networks (ANN) are machine learning models inspired by the structure of the human brain. The acronym “ANN” stands for Artificial Neural Network.
An ANN consists of three main layers:
• Input Layer: Receives the input data.
• Hidden Layers: Perform computations and extract meaningful features.
• Output Layer: Produces the final result.
Each layer contains nodes (neurons), and the values of these nodes are determined by multiplying the values from the previous layer with weighted connections and summing them. By continuously adjusting these weights, the network learns to recognize patterns and make predictions.

Deep learning is a subset of artificial neural networks where the number of hidden layers (Hidden Layers) is three or more. It is used to solve complex problems. The more hidden layers and nodes in each layer, the more computations are required, necessitating higher-performance neural network systems.
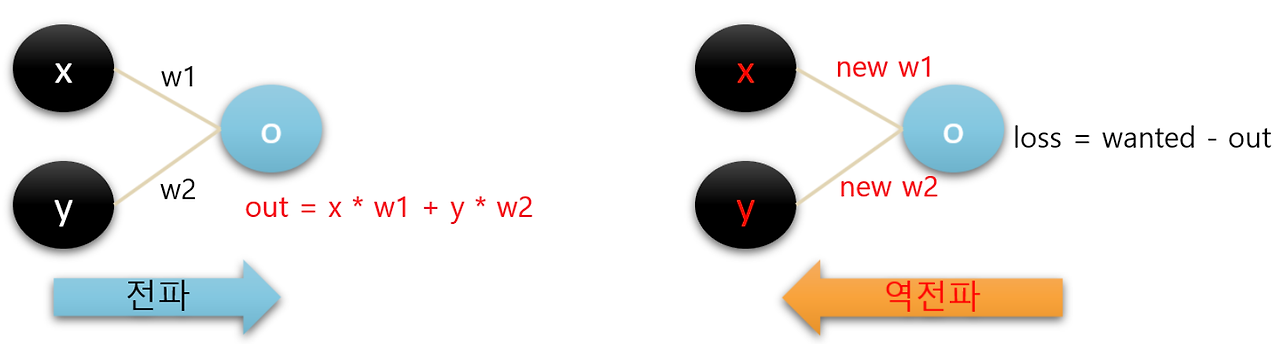
8) Forward Propagation and Backpropagation
In artificial neural networks, the model produces an output, and then the difference between the output and the desired value is used to adjust the network. The process of generating an output is called propagation (forward propagation). During this process, the value of each node is determined by summing the weighted values from the previous nodes.
When adjusting the difference between the desired output and the computed output, the neural network learns by modifying the weights of the connections between nodes. This adjustment process is known as backpropagation. The process can be visually represented as follows.
9) Activation Function
After calculating the sum of the weighted values from previous nodes, the neural network applies a specified function to transform this value. This function is called the activation function.
Activation functions have been used since the early days of neural networks. Initially, differentiable functions like the sigmoid and tanh functions were commonly used. Among them, the sigmoid function was widely adopted, but it presented issues such as the vanishing gradient problem and slow backpropagation. As the number of hidden layers increased, the weight values propagated from the input layer to hidden layers barely changed, making deep networks difficult to train effectively.
To address this issue, deep learning models often use the ReLU (Rectified Linear Unit) activation function in hidden layers. ReLU uses a simple linear function for positive values, solving the vanishing gradient problem and improving backpropagation speed. However, ReLU has the drawback that negative input values are ignored, leading to a potential loss of information. To address this, alternative activation functions such as SELU (Scaled Exponential Linear Unit), which can handle negative values, have been introduced.
Necessity of Activation Functions
Non-linear activation functions are essential for building multi-layer artificial neural networks. If only a linear activation function (e.g., y = ax) were used, or if no activation function were applied, a multi-layer neural network would be mathematically equivalent to a single-layer neural network. In other words, without non-linearity, deep networks would lose their ability to model complex patterns, making activation functions a crucial component of deep learning architectures.

If an activation function were not used in a multi-layer neural network, as shown in the diagram, then in the left-side network, node 1 would compute the value , and node 2 would be calculated in a similar way. Ultimately, the output node o would take the form of . This means that the multi-layer network would essentially be equivalent to a simple single-layer neural network. This is why non-linear activation functions are essential.
10) XOR Problem in a Single-Layer Neural Network
When neural networks first emerged, researchers realized that even a simple exclusive OR (XOR) problem was difficult to solve using a single-layer neural network. The XOR function is a classic example where linear classifiers fail, as it is not linearly separable.
A single-layer network cannot solve the XOR problem effectively. However, a multi-layer network can solve XOR by introducing hidden layers that transform the input space. While multi-layer networks allow for a solution, early implementations struggled with efficient training, making XOR an important historical challenge in the development of neural networks.
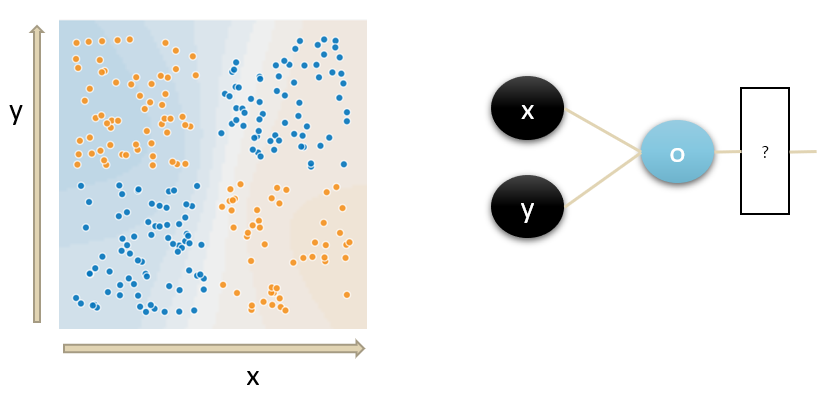
In the diagram, the left side represents the exclusive OR (XOR) problem for two input values. If we attempt to implement this using a single-layer neural network as shown on the right, the output O would be computed as:
This results in a linear decision boundary that cannot separate the XOR dataset properly, regardless of the activation function used.
To properly classify XOR, the output should ideally be expressed in a form such as:
However, using only summation-based computations makes it difficult to achieve this transformation, highlighting the limitations of single-layer neural networks in solving non-linearly separable problems like XOR.
11) Visual Pages for Simple Input Processing
Today, most deep learning implementations rely on frameworks such as TensorFlow or PyTorch. Once a deep learning model is set up, the programming aspect becomes minimal, as many tasks are standardized and automated.
If deep learning could be configured visually, with real-time monitoring and inspection tools, non-programmers would also be able to leverage deep learning for various tasks more easily.
Currently, the TensorFlow website provides a visual tool where users can experiment with deep learning using simple examples. In the future, it is expected that complex AI models will no longer require in-depth programming knowledge, and users will be able to develop AI solutions through intuitive visual tools rather than complex code-based libraries.
https://playground.tensorflow.org
Tensorflow — Neural Network Playground
Tinker with a real neural network right here in your browser.
playground.tensorflow.org
On the Playground TensorFlow website, users can visually observe how simple input patterns are processed. This interactive tool allows users to experiment with different neural network configurations and see how AI models learn from data.
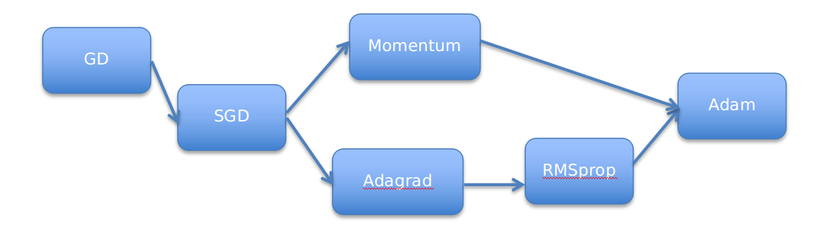
12) Finding Solutions: Optimizer
In artificial neural networks, backpropagation is used to adjust the weights based on the error in the output. Mathematically, this process is similar to finding the solution of a function. The method used for this optimization is called Gradient Descent.
In traditional mathematics, solutions are typically found using 2D inputs, but neural networks operate on multi-dimensional inputs, making optimization more complex. As a result, various optimization techniques have been proposed to efficiently find the optimal solution in high-dimensional spaces.
13) Deep Learning
The recent development of deep learning is largely due to advancements in hardware performance, which previously could not support deep artificial neural networks (ANNs). Neural networks require extensive matrix computations, involving numerous multiplication and addition operations. However, matrix computations can be significantly accelerated through parallel processing, making graphical processing units (GPUs) ideal for this task.
GPUs are designed for parallel computation, primarily for handling numerous vertices in computer graphics. When processing vertices, GPUs perform matrix multiplications using 4x4 transformation matrices. By extending this capability, GPUs can efficiently handle more complex matrix operations, which are fundamental to deep learning.
Modern deep learning libraries are designed to leverage the power of GPUs for computation. Two of the most widely used libraries are TensorFlow and PyTorch. Currently, these libraries rely on NVIDIA GPUs using CUDA, NVIDIA’s parallel computing platform.
TensorFlow, developed by Google, also supports TPUs (Tensor Processing Units)—specialized hardware designed specifically for deep learning. While Google’s TPUs are not available for direct purchase, they can be accessed via Google Colab, a cloud-based platform.
The initial version of AlphaGo, Google’s AI system for playing Go, utilized CUDA for GPU acceleration. However, the improved AlphaGo Lee (which competed against Go champion Lee Sedol, 9-dan) was powered by Google TPUs, demonstrating the increasing role of specialized AI hardware in deep learning.
Introduction to Reinforcement Learning
1) AlphaGo
AlphaGo is the first AI-based Go program to defeat a professional player. Earlier Go-playing AI programs were estimated to have the skill level of an amateur 4-kyu player, though their actual performance was often lower. However, AlphaGo defeated Lee Sedol, a 9-dan professional and one of the world’s top players, winning four out of five games in their historic match.
AlphaGo was developed by DeepMind, a subsidiary of Google.
The initial version of AlphaGo, known as AlphaGo DeepMind, was trained in collaboration with professional Go player Fan Hui. It was originally run on a hardware setup consisting of 1,202 CPUs and 176 GPUs and required several months of training. The version that competed against Lee Sedol, called AlphaGo Lee, replaced 176 GPUs with 48 TPUs for better performance.
Subsequent versions, AlphaGo Master and AlphaGo Zero, achieved even greater efficiency. AlphaGo Zero, in particular, used only four TPUs and demonstrated unprecedented dominance, winning 100 out of 100 games against the previous AlphaGo versions.
The initial version of AlphaGo was trained using a vast database of professional Go games and later improved through reinforcement learning. The introduction of AlphaGo significantly increased awareness and interest in reinforcement learning. In contrast, AlphaGo Zero was trained purely through reinforcement learning, without relying on human gameplay data.

AlphaGo played a major role in popularizing deep learning and bringing renewed attention to artificial neural networks.
2) Examples of Reinforcement Learning
One of the most famous examples of reinforcement learning is AlphaGo itself. Its match against Lee Sedol 9-dan was a historic event that captured worldwide attention.
After AlphaGo, reinforcement learning has been widely applied in gaming. It has been demonstrated in various games, including Atari games and StarCraft, showcasing AI’s ability to play and master complex games using reinforcement learning techniques.
'Lecture > Creating an AI Reversi Game' 카테고리의 다른 글
| Introduction to Reversi(Othello) Game (2) | 2025.02.05 |
|---|
